




go语言测试
以下运行结果为go1.18 linux/amd64
运行go help test会有对应介绍描述
运行go help testfunc有对应的使用测试例子
运行go help testflag有对应的参数值使用介绍
单元测试
单元测试是程序开发者适用一段代码来验证另外一段代码写的是否符合预期的一种相对高效的自我测试方法
1、使用
- 单元测试go文件,必须命名成xxx_test.go
- 方法名必须以Test开头,如:Test_xxx或TestXxx
- 方法使用testing.T形参接收,如使用 go test xxx_test.go -v -run Test_xxx
2、示例
代码:
package main_test
import(
"testing"
"fmt"
)
func Test_main1(t *testing.T){
fmt.Println("test")
}
func Test_main2(t *testing.T){
fmt.Println("test2")
}
运行结果:
m2@m2:tmp$ go test main_test.go -v -run Test_main1
=== RUN Test_main1
test
--- PASS: Test_main1 (0.00s)
PASS
ok command-line-arguments 0.001s
m2@m2:tmp$ go test main_test.go -v -run Test_main2
=== RUN Test_main2
test2
--- PASS: Test_main2 (0.00s)
PASS
ok command-line-arguments 0.001s
注:
go test -v执行测试用例时打印测试详情
go test -run执行测试函数
基准测试
基准测试是测量一个程序在固定工作负载下的性能。
1、使用
- 单元测试go文件,必须命名成xxx_test.go
- 方法名必须以Benchmark开头,如:Benchmark_xxx或BenchmarkXxx
- 方法使用testing.B形参接收,如使用 go test -bench=. xxx_test.go
2、示例
为了展示有相对意义的基准测试,分两种情况示例,普通基准和并行基准
-
普通基准
代码:–为拼接字符串操作,看直接+=与使用strings.Builder的性能差距package main_test import( "testing" "strings" ) func Benchmark_str(b *testing.B){ for i:=0; i<b.N; i++{ var s string for i:=0; i<25565; i++{ s+="a" } } b.Log(b.N) } func Benchmark_buffer(b *testing.B){ for i:=0; i<b.N; i++{ var b strings.Builder for i:=0; i<25565; i++{ b.WriteString("a") } b.String() } b.Log(b.N) }运行结果:m2@m2:tmp$ go test -bench=. string_test.go goos: linux goarch: amd64 cpu: Intel(R) Core(TM) i5-8300H CPU @ 2.30GHz Benchmark_str-8 32 36241313 ns/op --- BENCH: Benchmark_str-8 string_test.go:13: 1 string_test.go:13: 32 Benchmark_buffer-8 22980 52360 ns/op --- BENCH: Benchmark_buffer-8 string_test.go:23: 1 string_test.go:23: 100 string_test.go:23: 10000 string_test.go:23: 22980 PASS ok command-line-arguments 2.931s中间数字为1秒(默认为1秒)运行的次数, 越多性能越好. 后面数字为运行一次花费的时间,越少性能越好. -
并行测试
代码:–为测试使用Mutex、RMMutex和atomic数字相加的性能区别package main_test import( "sync" "testing" "sync/atomic" ) func Benchmark_MutexCount(b *testing.B){ var count uint64 = 0 var lock sync.Mutex count = 0 b.ResetTimer() //并行 b.RunParallel(func(pb *testing.PB){ for pb.Next(){ lock.Lock() count++ lock.Unlock() } }) b.StopTimer() b.Log(count) } func Benchmark_AtomicCount(b *testing.B){ var count uint64 = 0 b.ResetTimer() b.RunParallel(func(pb *testing.PB){ for pb.Next(){ atomic.AddUint64(&count, 1) } }) b.StopTimer() b.Log(count) } func Benchmark_RWMutexCount(b *testing.B){ var count uint64 = 0 var lock sync.RWMutex count = 0 b.ResetTimer() b.RunParallel(func(pb *testing.PB){ for pb.Next(){ lock.Lock() count++ lock.Unlock() } }) b.StopTimer() b.Log(count) }运行结果:m2@m2:tmp$ go test -bench=. count_test.go -v goos: linux goarch: amd64 cpu: Intel(R) Core(TM) i5-8300H CPU @ 2.30GHz Benchmark_MutexCount count_test.go:22: 1 count_test.go:22: 100 count_test.go:22: 10000 count_test.go:22: 1000000 count_test.go:22: 27940495 Benchmark_MutexCount-8 27940495 44.04 ns/op Benchmark_AtomicCount count_test.go:34: 1 count_test.go:34: 100 count_test.go:34: 10000 count_test.go:34: 1000000 count_test.go:34: 76749661 Benchmark_AtomicCount-8 76749661 15.48 ns/op Benchmark_RWMutexCount count_test.go:50: 1 count_test.go:50: 100 count_test.go:50: 10000 count_test.go:50: 1000000 count_test.go:50: 21671960 Benchmark_RWMutexCount-8 21671960 55.56 ns/op PASS ok command-line-arguments 3.744s由此可见atomic的性能远远大于其它,这是因为atomic属于cpu级别的指令,并非锁
模糊测试
go1.18之后就支持原生goapi进行模糊测试.
何为模糊测试?模糊测试是一种自动测试,它不断地操作程序的输入以发现错误.
原文
Fuzzing is a type of automated testing which continuously manipulates inputs to a program to find bugs.
Go fuzzing uses coverage guidance to intelligently walk through the code being fuzzed to find and report
failures to the user. Since it can reach edge cases which humans often miss, fuzz testing can be
particularly valuable for finding security exploits and vulnerabilities.
1、使用
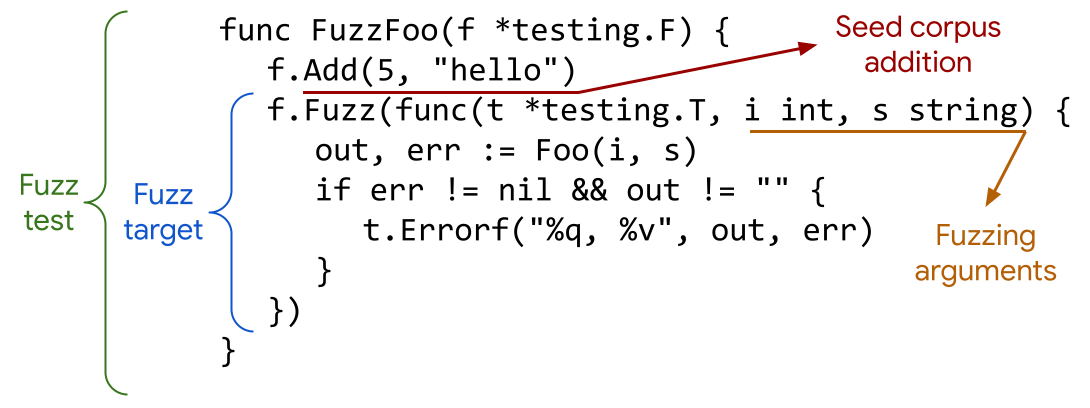
- 单元测试go文件,必须命名成xxx_test.go
- 方法名必须以Fuzz开头,如:Fuzz_xxx或FuzzXxx
- 方法使用testing.F形参接收,如使用 go test -fuzz=Fuzz xxx_test.go
2、示例
从单元到模糊,讲一下有了单元测试为什么需要模糊测试
以下代码为一段字符串逆转
func Reverse(s string) string {
b := []byte(s)
for i, j := 0, len(b)-1; i < len(b)/2; i, j = i+1, j-1 {
b[i], b[j] = b[j], b[i]
}
return string(b)
}
为测试他的正确性,我们一般会选择单元测试
func TestReverse(t *testing.T) {
testcases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{" ", " "},
{"!12345", "54321!"},
}
for _, tc := range testcases {
rev := Reverse(tc.in)
if rev != tc.want {
t.Errorf("Reverse: %q, want %q", rev, tc.want)
}
}
}
查看运行结果
m2@m2:tmp$ go test fuzz_test.go -v -run Test
=== RUN TestReverse
--- PASS: TestReverse (0.00s)
PASS
ok command-line-arguments 0.001s
此处有个小技巧 -run 后面不需要跟全部的方法名,有最左匹配
思考以下,现在程序真的正确了吗?有没有我们没有考虑的情况,以上测试用例有数字、大小写字母、符号和空格,中文呢?所以我们新增一个测试用例
testcases := []struct {
in, want string
}{
{"Hello, world", "dlrow ,olleH"},
{" ", " "},
{"!12345", "54321!"},
{"m的二次方","方次二的m"},
}
run
m2@m2:tmp$ go test fuzz_test.go -v -run Test
=== RUN TestReverse
fuzz_test.go:26: Reverse: "\xb9\x96桬挺䄚\xe7m", want "方次二的m"
--- FAIL: TestReverse (0.00s)
FAIL
FAIL command-line-arguments 0.002s
FAIL
我们看到测试是不通过的, 那么还有没有其他情况?如果 项目直接上线,经过用户体验才发现这个问题,会不会造成损失,相应责任又由谁承担呢?
这个时候,我们的代码应该去跑模糊测试。单元测试只是在我们局限想好的、理想的环境下进行的,给定输入和正确的输出结果,最后运行结果和正确结果对比的操作.
模糊测试则是我们不知道它的输入是什么,我们只能尽可能捕捉正确的结果.
模糊测试: 传参为一开始的三个,没有中文情况,模拟有我们没发现出来的边界条件
func FuzzReverse(f *testing.F) {
testcases := []string{"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Use f.Add to provide a seed corpus
}
f.Fuzz(func(t *testing.T, orig string) {
rev := Reverse(orig)
doubleRev := Reverse(rev)
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
//判断是不是有效的uft8编码符号组成
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}
m2@m2:tmp$ go test -fuzz=Fuzz fuzz_test.go -run Fuzz
fuzz: elapsed: 0s, gathering baseline coverage: 0/9 completed
fuzz: elapsed: 0s, gathering baseline coverage: 9/9 completed, now fuzzing with 8 workers
fuzz: elapsed: 0s, execs: 116 (3918/sec), new interesting: 0 (total: 9)
--- FAIL: FuzzReverse (0.03s)
--- FAIL: FuzzReverse (0.00s)
fuzz_test.go:42: Reverse produced invalid UTF-8 string "\xbf\xd4"
Failing input written to testdata/fuzz/FuzzReverse/72a8282035fd0805dcc9561c9b4f02da5766eea545a41bdf367a215fe471aa00
To re-run:
go test -run=FuzzReverse/72a8282035fd0805dcc9561c9b4f02da5766eea545a41bdf367a215fe471aa00
FAIL
exit status 1
FAIL command-line-arguments 0.034s
结果是失败的,与此同时当前文件夹下面会生成一个testdata文件夹,里面存放着我们运行失败的测试用例
m2@m2:tmp$ ls
count_test.go fuzz_test.go main_test.go string_test.go testdata
m2@m2:tmp$ cat testdata/fuzz/FuzzReverse/72a8282035fd0805dcc9561c9b4f02da5766eea545a41bdf367a215fe471aa00
go test fuzz v1
string("Կ")
oh my god,"Կ"这是哪个国家语言啊!我们可爱的用户会不会输入这个奇奇怪怪的东西呢??
我们此刻需要修改Reverse函数和FuzzReverse函数, 返回两个值,遇见不能正常解析的则返回错误
func Reverse(s string) (string, error) {
if !utf8.ValidString(s) {
return s, errors.New("input is not valid UTF-8")
}
r := []rune(s)
for i, j := 0, len(r)-1; i < len(r)/2; i, j = i+1, j-1 {
r[i], r[j] = r[j], r[i]
}
return string(r), nil
}
func FuzzReverse(f *testing.F) {
testcases := []string {"Hello, world", " ", "!12345"}
for _, tc := range testcases {
f.Add(tc) // Use f.Add to provide a seed corpus
}
f.Fuzz(func(t *testing.T, orig string) {
rev, err1 := Reverse(orig)
if err1 != nil {
return
}
doubleRev, err2 := Reverse(rev)
if err2 != nil {
return
}
if orig != doubleRev {
t.Errorf("Before: %q, after: %q", orig, doubleRev)
}
if utf8.ValidString(orig) && !utf8.ValidString(rev) {
t.Errorf("Reverse produced invalid UTF-8 string %q", rev)
}
})
}
m2@m2:tmp$ go test -fuzz=Fuzz fuzz_test.go
fuzz: elapsed: 0s, gathering baseline coverage: 0/10 completed
fuzz: elapsed: 0s, gathering baseline coverage: 10/10 completed, now fuzzing with 8 workers
fuzz: elapsed: 3s, execs: 470843 (156922/sec), new interesting: 31 (total: 41)
fuzz: elapsed: 6s, execs: 938604 (155927/sec), new interesting: 31 (total: 41)
fuzz: elapsed: 9s, execs: 1392477 (151299/sec), new interesting: 31 (total: 41)
fuzz: elapsed: 12s, execs: 1849305 (152244/sec), new interesting: 31 (total: 41)
fuzz: elapsed: 15s, execs: 2309802 (153492/sec), new interesting: 31 (total: 41)
fuzz: elapsed: 18s, execs: 2773352 (154523/sec), new interesting: 31 (total: 41)
它会一直跑下去,没有错误基本就通过了,一个健全的函数就诞生了.也可以使用-fuzztime 30s限制时间
m2@m2:tmp$ go test -fuzz=Fuzz -fuzztime 30s fuzz_test.go
fuzz: elapsed: 0s, gathering baseline coverage: 0/41 completed
fuzz: elapsed: 0s, gathering baseline coverage: 41/41 completed, now fuzzing with 8 workers
fuzz: elapsed: 3s, execs: 476844 (158936/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 6s, execs: 956825 (159974/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 9s, execs: 1409433 (150874/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 12s, execs: 1866869 (152457/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 15s, execs: 2323710 (152311/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 18s, execs: 2786804 (154375/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 21s, execs: 3251751 (154978/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 24s, execs: 3710995 (152983/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 27s, execs: 4166758 (151985/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 30s, execs: 4624541 (152374/sec), new interesting: 3 (total: 44)
fuzz: elapsed: 30s, execs: 4624541 (0/sec), new interesting: 3 (total: 44)
PASS
ok command-line-arguments 30.104s
总结
一个优秀的程序员是能写出健壮的代码的, 自我测试是必须会的.但go语言的测试并不只有我上面提到这些, 或许还有很多高效便捷的使用方式等着我挖掘.
常用命令
go test执行当前包中全部测试用例,不包括 benchmark测试
go test -bench=.执行当前包中全部测试用例,包括 benchmark测试
go test -v执行测试用例时打印测试详情
go test -race检查当前测试代码是否存在竞争异常,用于检查线程安全
go test -cover检查测试代码覆盖率
参考
b站UP–吃货发明家 https://www.bilibili.com/video/BV1XD4y1C7Bg
https://go.dev/doc/tutorial/fuzz
Q.E.D.